
13
年
专
注
于
网
站
建
设






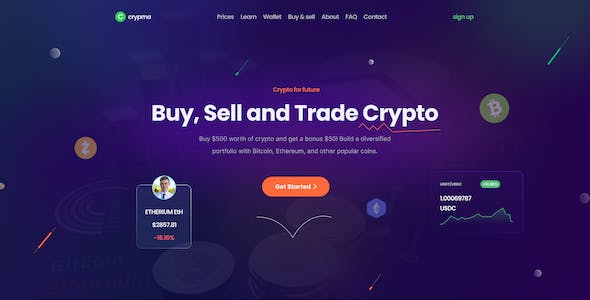
恶意爬虫是指通过自动化程序来访问网站,获取网站数据,进行非法活动或者侵害网站利益的一类威胁。恶意爬虫不仅会导致网站流量过大,还可能占用网站资源,对正常用户产生负面影响。为了保护网站的正常运行和用户体验,网站管理员应采取一系列措施来防御恶意爬虫的攻击。
在防御恶意爬虫攻击时,网站管理员可以采用以下常用方法:
1. 限制访问频率:设置网站访问频率限制,对指定IP地址的请求进行限制。通过设置访问频率限制,可以减少恶意爬虫对网站的访问次数,保护网站资源。
2. 验证码:在关键操作页面,如登录、注册、评论等地方使用验证码。验证码是一种基于图像识别的验证方式,可以有效防止恶意程序的自动化操作。
3. User-Agent检测:通过检测User-Agent字段,判断请求是否来自真实用户。恶意爬虫通常通过伪造User-Agent字段来隐藏自己的身份,所以通过检测User-Agent可以辨别出恶意爬虫的请求。
4. Robots.txt文件:通过在网站根目录下放置Robots.txt文件,指定哪些页面可以被爬虫访问,哪些页面禁止被访问。网站管理员可以通过编辑Robots.txt文件,限制恶意爬虫的访问范围。
5. IP封禁:通过监控网站的访问日志,及时发现可疑IP地址,并将其列入黑名单,限制其访问网站。封禁可疑IP地址是一种常见的防御恶意爬虫攻击的手段。
6. 人机验证:通过人机验证技术,如滑块验证码、点击验证码等,判断请求是否来自真实用户。人机验证可以有效区分人类用户和恶意爬虫,提升网站的安全性。
7. 反爬虫策略:在网站代码中添加一些反爬虫策略,如隐藏关键数据、使用动态生成页面等。这些策略可以增加恶意爬虫破解的难度,减少被爬虫访问的可能性。
除了以上常用方法,网站管理员还可以根据实际情况选择其他防御手段,如使用CDN服务、使用Web应用防火墙等。在防御恶意爬虫的过程中,需要持续监控网站访问日志,并及时更新防御策略,以应对不断变化的恶意爬虫攻击。




 确定建站目标
确定建站目标 深度调研策划
深度调研策划 建立视觉体系
建立视觉体系 创意视觉设计
创意视觉设计 前端交互开发
前端交互开发 短视频推广
短视频推广 短视频竞价
短视频竞价 短视频矩阵
短视频矩阵 抖音视频营销
抖音视频营销 媒体软文营销
媒体软文营销 网站SEO优化
网站SEO优化 小程序开发
小程序开发 系统私有定制
系统私有定制 APP设计开发
APP设计开发 数字运维监测
数字运维监测 网站等保服务
网站等保服务 集锦站群系统
集锦站群系统 集锦ERP系统
集锦ERP系统 集锦知识付费
集锦知识付费 数字内容系统
数字内容系统 集锦电商系统
集锦电商系统 生物医药网站建设
生物医药网站建设 IT科技网站建设
IT科技网站建设 网站集群网站建设
网站集群网站建设 教育培训网站建设
教育培训网站建设 智慧党建网站建设
智慧党建网站建设 上市公司网站建设
上市公司网站建设
 立即咨询
立即咨询





 立即咨询
立即咨询



 拨打电话获取报价
拨打电话获取报价








